
Result How to Fine-Tune Llama 2 In this part we will learn about all the steps required to fine-tune the Llama 2 model with 7 billion parameters. Contains examples script for finetuning and inference of the Llama 2 model as well as how to use them safely. Result The following tutorial will take you through the steps required to fine-tune Llama 2 with an example dataset using the Supervised Fine-Tuning SFT approach. Result In this guide well show you how to fine-tune a simple Llama-2 classifier that predicts if a texts sentiment is positive neutral or negative. Result In this notebook and tutorial we will fine-tune Metas Llama 2 7B Watch the accompanying video walk-through but for Mistral here If youd like to see that..
Scale Ai
Meta developed and publicly released the Llama 2 family of large language models LLMs a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have double the context length of Llama 1 Llama 2 encompasses a series of generative text. Llama 2 comes in a range of parameter sizes 7B 13B and 70B as well as pretrained and fine-tuned variations. The Llama2 7B model on huggingface meta-llamaLlama-2-7b has a pytorch pth file consolidated00pth that is 135GB in size The hugging face transformers compatible model meta. Vocab_size 32000 hidden_size 4096 intermediate_size 11008 num_hidden_layers 32 num_attention_heads 32 num_key_value_heads None hidden_act silu max_position_embeddings 2048..
Customize Llamas personality by clicking the. . Introducing Llama 2 70B in MLPerf Inference v40 For the MLPerf Inference v40 round the working group. Llama Chat uses reinforcement learning from human feedback to ensure safety and helpfulness. Llama 2 70b stands as the most astute version of Llama 2 and is the favorite among users. Llama 2 is available in a variety of sizes with parameters ranging from 7 billion to 70 billion and includes both pretrained..
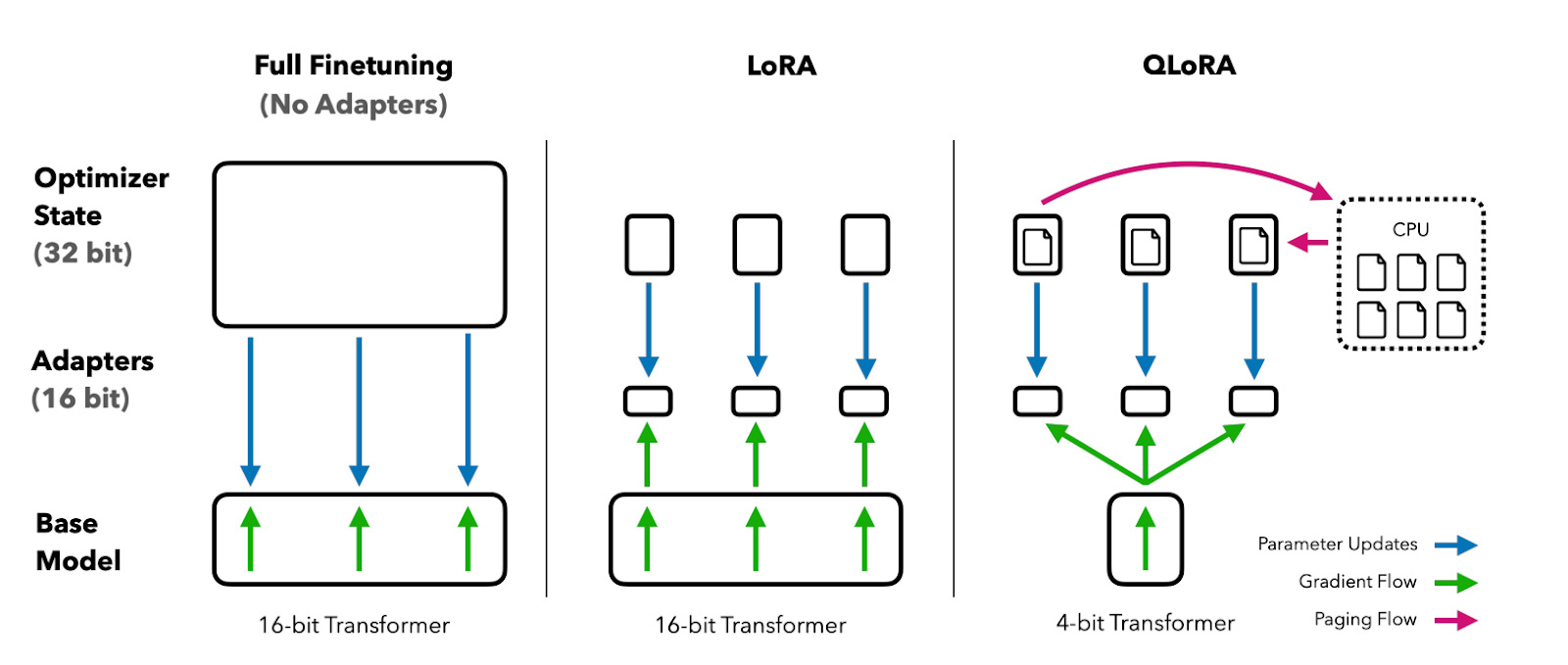
Datacamp
This release includes model weights and starting code for pre-trained and fine-tuned Llama language models ranging from 7B to 70B parameters This repository is intended as a minimal. Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the launch with comprehensive integration in Hugging. The llama-recipes repository is a companion to the Llama 2 model The goal of this repository is to provide a scalable library for fine-tuning Llama 2 along with some example scripts and. . Code Llama is a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models infilling capabilities support for large input contexts and..



Komentar